

-117604c88dfb4fe3b996a5bf278e840e.JPG)
前言
Manus的可视化交互给我们所有人都留下了非常深刻的映像,这种完全由AI来操作电脑的冲击性真的不下雨第一次使用手机,第一次使用搜索引擎的暗中冲击感!这也怪不得他会在半个月内就实现了病毒式的传播,让大家都都直观地认识到当前的人工智能到底有多么强大。在此,我们继续回顾一下manus的演示视频:
https://www.bilibili.com/video/BV1zZ9RYcEpL/?spm_id_from=333.337.search-card.all.click&vd_source=ac662153664b2a94b51bd83670cf6d80
Manus的地址:https://manus.im
那么,视频中最炫酷的AI操作电脑的部分是怎么实现的呢?其实就是Browser Use:https://github.com/browser-use/browser-use
致敬完Manus的厉害,现实问题是,manus这个网站国内不可用,最近的消息甚至是他跑路了,不准备在中国区域开放了。于是没办法,作者我只能自己动手丰衣足食了。
先来贴一个项目地址,大家有条件的话给个star~: https://github.com/nolaurence/java-manus
然后就是介绍核心的浏览器工具的实现了,这一块也是耗时最大的部分:
浏览器工具的实现
在manus的介绍里,基于playwright的浏览器操作工具非常重要,可以称为 Gen AI (生成式AI)最重要的一个工具。里面最难的技术就是如何在无显示器环境中启动浏览器并提供给前端使用。
那么这个核心的工具要怎么实现呢,请开始我的表演~~
我从头实现了浏览器启动和推流。现在来简单介绍下实现的方法:
- 主要的架构如下
[前端]
↓ (请求视频流)
[Backend 服务]
↓ (调用 Worker API)
[Worker 服务]
↓ (Playwright + ffmpeg)
[浏览器画面 → HLS 流]
从架构中可以看出,浏览器的推流是worker中将浏览器画面实时使用ffmpeg推流出来的,那么后端服务又是怎么调用worker上的浏览器的呢。
在我的实现中,主要使用了开源库playwright-mcp来使用CDP协议连接到worker上的chromium浏览器,浏览器的安装则实在docker打包时使用Dockerfile实现的。
开源库的地址贴在这里:https://github.com/microsoft/playwright-mcp
实际在worker上启动playwright-mcp服务的命令是这个:
ProcessBuilder pb = new ProcessBuilder(
"npx", "@playwright/mcp@" + PLAYWRIGHT_MCP_VERSION,
"--browser", "chrome",
"--caps", "pdf",
"--cdp-endpoint", "http://127.0.0.1:8222",
"--output-dir", mcpLogDir,
"--user-data-dir", mcpLogDir,
"--port", MCP_SERVER_PORT,
"--viewport-size", "1280,1024"
);
实际的命令是这样的:
npx @playwright-/mcp@0.0.39 --browser chrome --caps pdf --cdp-endpoint http://127.0.0.1:8222 --output-dir ./logs --user-data-dir ../dir --port 7500 --viewport-size 1280,1024
接下来就是其他组件的具体实现:
worker端的实现
主要需要集成javacv和javacv-platform两个库,负责实现ffmpeg的免安装和页面的抓取和推流
tip:ffmpeg的二进制文件由javacv-platform提供,不需要在worker容器中单独按照
chromium:必须在容器中安装好,并在应用中指定chromium的位置。
xvfb:创建虚拟显示器。
x11-vnc: 将显示器转换成可以vnc连接的组件
websockify:将vnc转换成前端novnc可以连接的websocket链接。
然后详细介绍各个组件的安装方式:
chromium的安装
这里贴的是dockerfile,直接添加sudo安装即可
RUN add-apt-repository ppa:xtradeb/apps -y && \
apt-get update && \
apt-get install -y chromium --no-install-recommends && \
apt-get clean && \
rm -rf /var/lib/apt/lists/*
这里需要解决科学上网问题,ppa:xtradeb/apps 在国内环境中无法正常添加,这也是最大的卡点
xvfb的安装:
还是直接贴dockerfile了:
FROM ubuntu:22.04
RUN mv /etc/apt/sources.list /etc/apt/sources.list.bak
# 替换 APT 源为清华大学镜像
RUN echo '# 默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释' > /etc/apt/sources.list && \
echo 'deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse' >> /etc/apt/sources.list && \
echo 'deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse' >> /etc/apt/sources.list && \
echo 'deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse' >> /etc/apt/sources.list && \
echo 'deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse' >> /etc/apt/sources.list
# Update and install basic tools and playwright deps
RUN apt-get update && apt-get install -y \
sudo \
bc \
curl \
wget \
gnupg \
software-properties-common \
xvfb \
x11vnc \
websockify \
libx11-xcb1 libxkbcommon0 x11-apps x11-utils \
fonts-liberation libgl1 libglib2.0-0 libsm6 \
libxrender1 libxcomposite1 libasound2 libxdamage1 \
imagemagick \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
这一段能把大部分需要的依赖和xvfb安装好
playwright的核心实现代码
首先添加依赖
<dependency>
<groupId>com.microsoft.playwright</groupId>
<artifactId>playwright</artifactId>
<version>1.52.0</version> <!-- 确保使用最新稳定版 -->
</dependency>
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>javacv-platform</artifactId>
<version>1.5.10</version> <!-- 检查最新版本 -->
</dependency>
架构介绍
先简单介绍下参考的开源项目的架构:
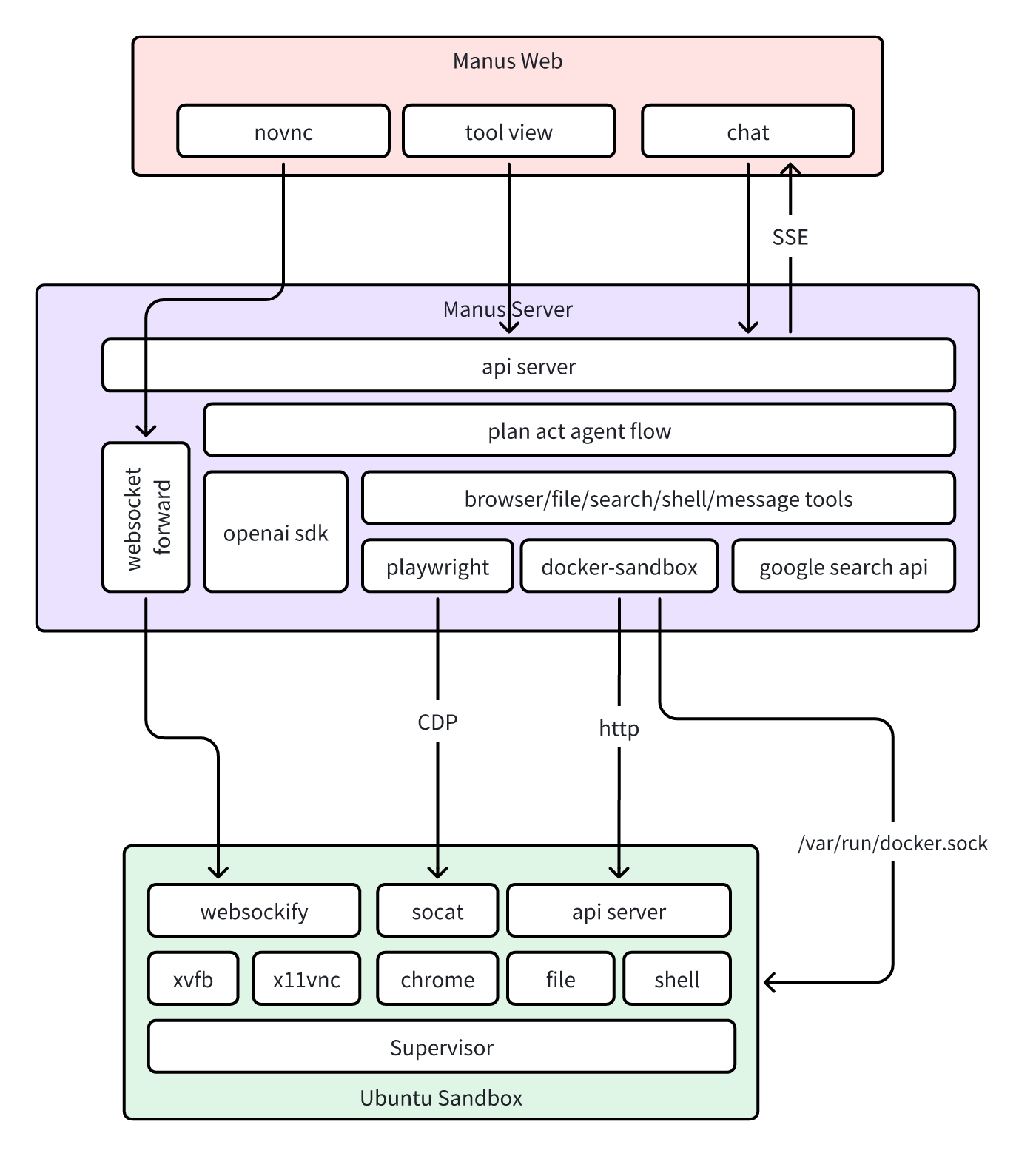
在实际的拉取代码而不是使用项目提供的镜像中发现了几个问题:
- chromium的xtrappa依赖外网环境,本地无法构建成功
- sandbox依赖supervisord的服务管理存在一些稳定性问题,导致sandbox容器经常失败,从而整个服务不可用
当然最主要的目的是作者想用java or go复刻一个,并根据自己所学去自己实现一个ReAct框架并调优ai的效果。
所以简单研究了下开源代码和技术方案后,将架构调整为下面这样:
[前端]
↓ (请求视频流)
[Backend 服务]
↓ (调用 Worker API)
[Worker 服务]
↓ (Playwright + ffmpeg)
[浏览器画面 → HLS 流]
详细架构如下
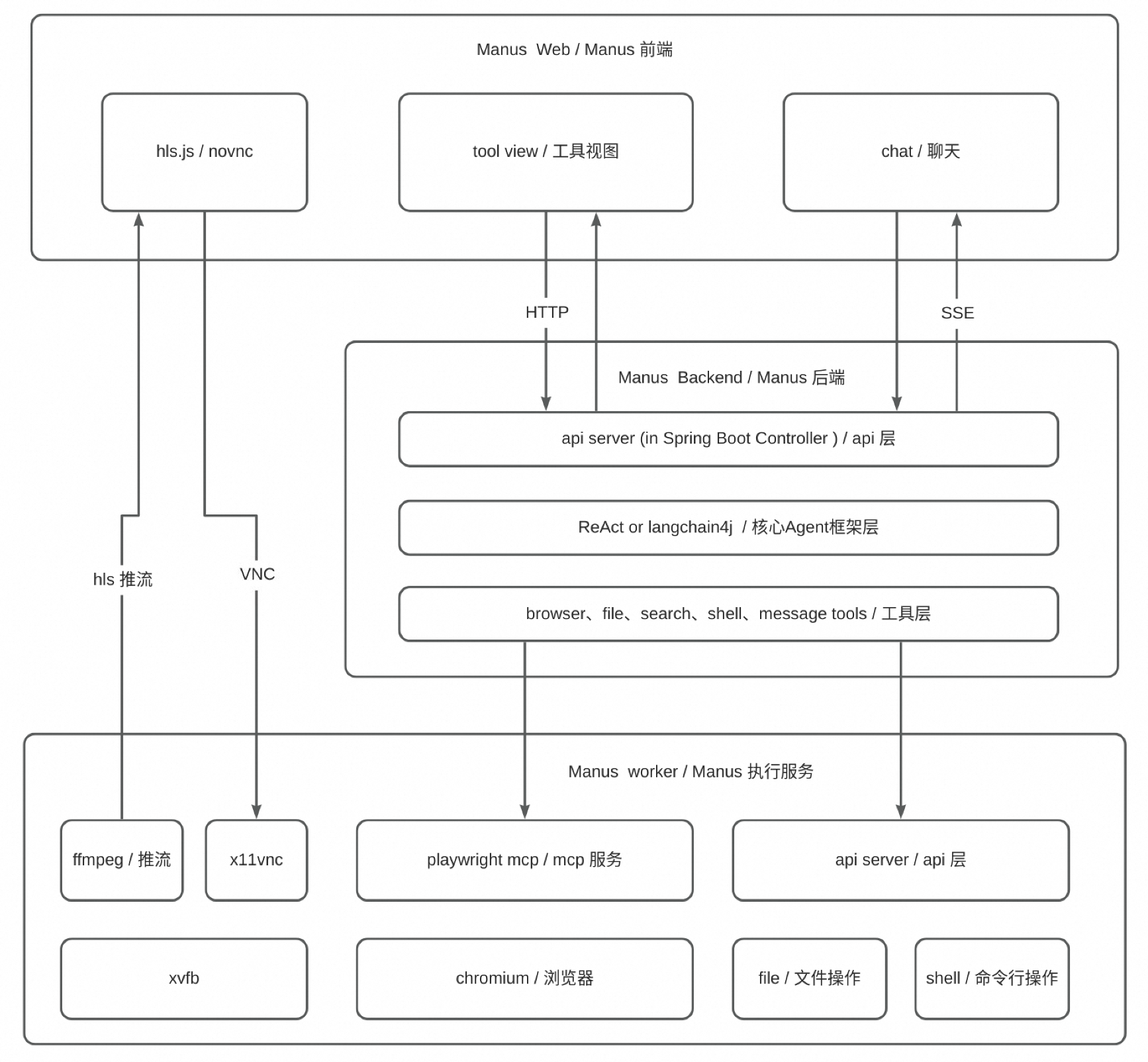
主要的变更点如下:
- 后端的Manus Worker 和 Manus Backend共享一个代码库,构建成同一个jar,只根据api和配置文件的不同区分其职责,方便代码的维护和共享。
- 前端改用react + tailwindcss实现,工程框架选用了umijs 而不是webpack 或者 vite
这样做的好处是前端不用单独使用一个容器host,而可以将css全部放到cdn或者整合到后端工程中以提升加载速度
- 直播方案除了vnc方案,还提供了安全性更高的hls推流方案
比如生成环境中,直接让用户可以通过vnc端口去操作浏览器机器可能会存在安全问题。
总体的数据流动
- 后端服务部署在7001端口上,并且通过http协议与worker连接,操作一些基本的功能,如浏览器启停,串流服务启停等。
- 后端服务的大模型通过mcp sdk连接到worker的7500端口,mcp server通过CDP(chrome debug protocol)的8222端口连接到浏览器。大模型推理出对应的操作命令后,直接使用mcp sdk中的mcp client调用即可。mcp client和mcp server的连接方式是,请求使用http,返回使用SSE协议的长连接。
- 串流和vnc链路都是浏览器将画面投放到xfvb虚拟显示器上,然后串流是ffmpeg将画面捕捉并以m3u8协议存储到本地,worker上的springboot工程提供m3u8协议的所有接口,后端服务仅实现转发功能,前端使用Hls.js实现直播流量的抓取并渲染到网页上。VNC功能则是x11-vnc将xfvb的画面透出一个TCP链接到5900端口,再由websockify将其转换成websocket流量到5902端口,使得前端可以使用novnc组件连接,后端服务也只是提供简单的转发服务。
完成上述建设,就能实现和manus一样的浏览器操作与实时的直播功能了。